Never Go Dark: Designing Crash Recovery for a Live Show
Published: / 7 min read
Updated:Table of Contents
It is easy to talk about resilience in vague, flattering language.
For a live rig, I think the more useful question is: if the engine process dies right now, what does the room see next?
That question shaped the persistence model in Supervision more than any database preference ever could.
The checkpoint is the live state, not the edit history
There are two very different categories of data in the system:
- Project data like scenes, palettes, patterns, effects, and group definitions
- Performance state like the active scene, active palette, active pattern, enabled effects, dimmer, blackout flag, BPM, and the last known laser preset
Project data can be edited, versioned, and reasoned about like application content. Performance state is the thing the room is currently looking at.
The recovery story cares about the second category.
That is why the Pi keeps a single-row performance checkpoint in SQLite. It is not trying to journal every subtle internal transition. It is trying to preserve the last meaningful live state so the rig can come back in a recognizable place after a restart.
That checkpoint is intentionally plain. It captures the full operator-facing state that matters in the moment:
- which scene is active
- which palette and pattern are active
- which effects are enabled
- master dimmer, blackout, and BPM
- the last known laser preset, if one has been recalled
That last bullet matters because laser is not some hypothetical future edge. In this system, Laser is shipped, integrated, and bounded by the Phase 8 Radiator design. If Radiator is in the rig, lastLaserPreset is part of the live state. If Radiator is absent, the rest of the system still works fine.
The command ordering is the design
The most important thing about the checkpoint is not the table schema. It is the order in which commands get applied.
In supervision, a state-changing command follows this shape:
function applyCommand(cmd: ClientCommand) { applyToHotState(state, cmd); worker.postMessage({ type: "setState", patch: resolveStatePatch(state) }); broadcastSceneSync(state); saveCheckpoint(db, state);}I like this ordering because it reflects what is most important in a live moment.
- Update the in-memory truth.
- Tell the engine worker so output can follow.
- Tell connected clients so the control surfaces stay consistent.
- Persist the checkpoint last.
That last part is deliberate. Disk is important, but it is not the most urgent consumer of an operator gesture. The room cares about output first. The screens care about convergence second. The database gets the remaining slot.
The inconsistency window is real, and bounded
That ordering creates a narrow inconsistency window.
If the process crashes after broadcasting state to clients but before writing the checkpoint, the saved state can be one event behind what a user just saw.
I accepted that on purpose.
I did not want to pay for stronger durability with a slower or more entangled control path, especially when the bounded failure mode is understandable:
- the checkpoint may be one change behind
- reconnecting clients will converge on that checkpoint
- the rig restarts into a coherent state instead of a blank default
That is a better live failure than trying to preserve perfection and risking more damage in the hot path.
This is the kind of trade that gets easier once you stop treating persistence as a moral purity test. The system does not need idealized consistency. It needs a recovery behavior that is legible and acceptable during a performance.
Why SQLite lives on the main thread
This part of the architecture follows directly from the engine-loop work: better-sqlite3 is synchronous, so it stays far away from the worker.
That means:
- checkpoint writes are blocking
- but they only block the main thread
- and the worker keeps doing engine work on its own thread
This is one of the quieter advantages of the split architecture. I can use a very straightforward persistence layer without dragging it through the timing-sensitive part of the system.
That is a recurring theme in this project: once the boundaries are right, the implementation gets simpler.
Restart behavior has to make sense on every surface
The checkpoint matters because the engine process is configured to come back automatically. On restart, Supi loads the last checkpoint, rebuilds the hot state, patches the worker, and starts accepting controller connections again.
That recovery path is not just about the Pi internally feeling better about itself. It is about what the operator sees next.
The iPad is still the primary control surface, so it needs to reconnect and land back on a coherent picture of the show. The iPhone companion is narrower by design, but it still has to resync to that same authoritative state instead of drifting off into its own little interpretation. After restart, both apps reconnect to the Pi, get the rebuilt state, and redraw from the same source of truth.
If Radiator is present, there is one more step: the last known laser preset is retained in the checkpoint and re-sent when the Radiator connection comes back. That does not mean the system has magical knowledge of the laser’s physical front panel. It means Supervision keeps the last successful preset recall it issued, and on reconnect it pushes that preset again so the laser side rejoins the recovered show state.
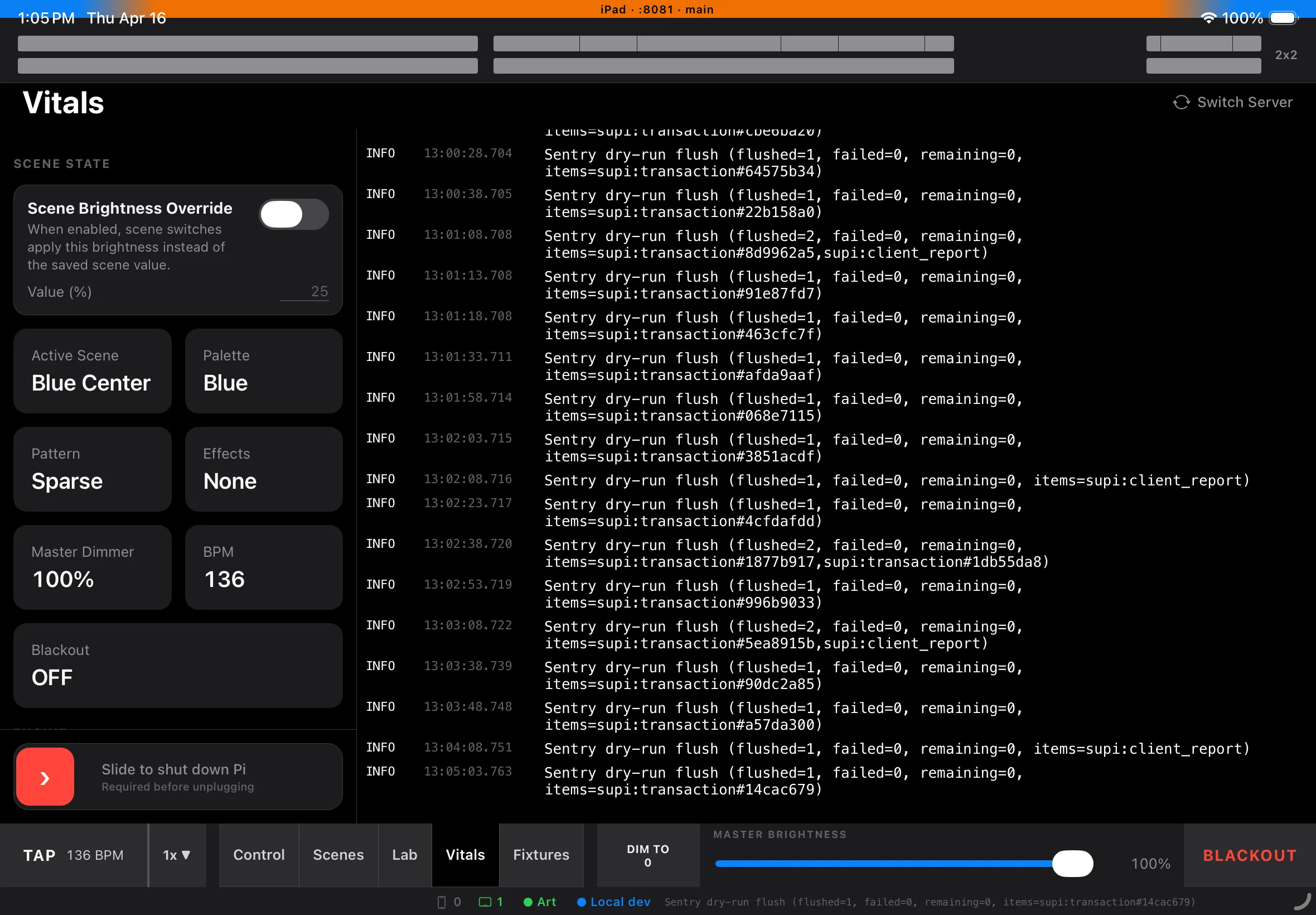
iPad Vitals view — live engine health, recovery signals, and operator-facing system status on the primary control surface.
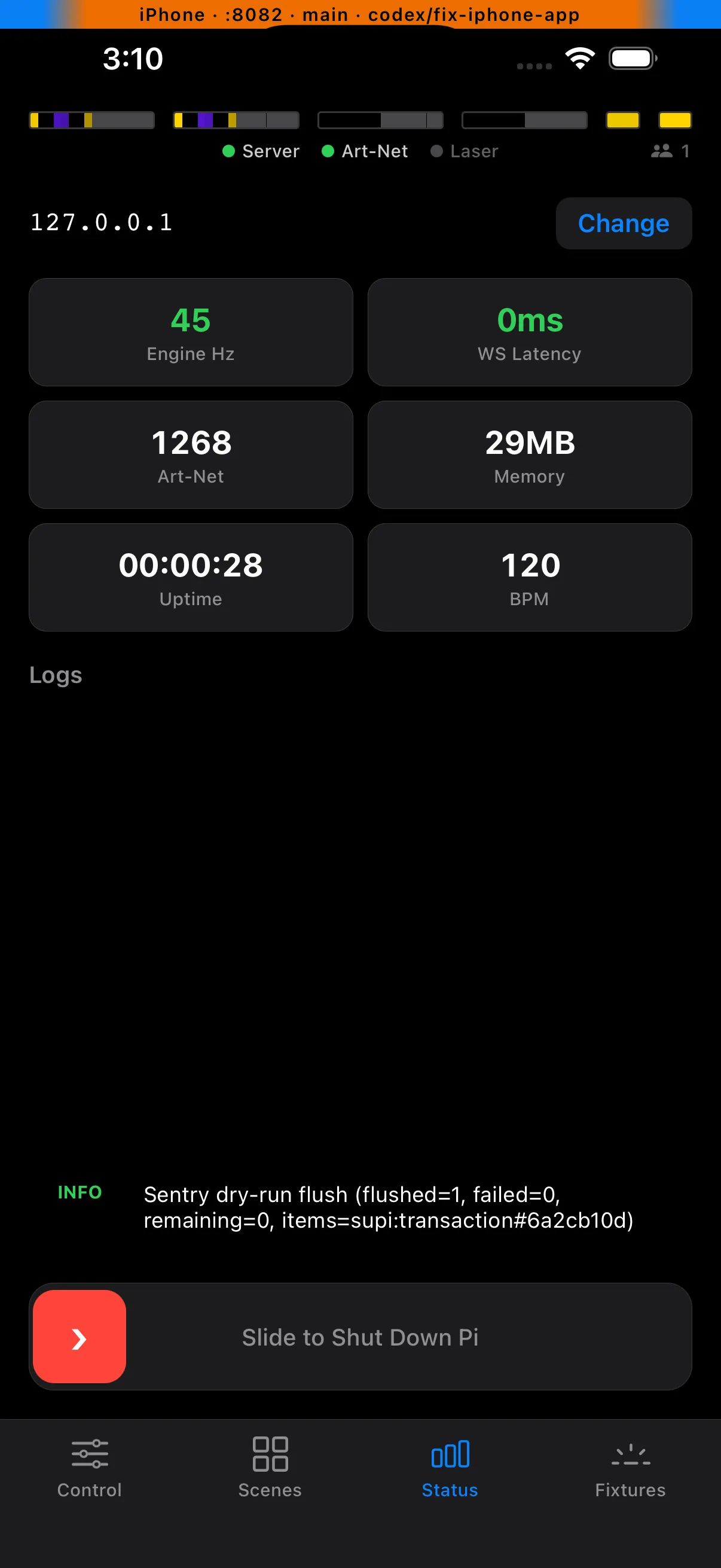
iPhone Status view — compact engine health, connection state, uptime, and logs from the companion client.
I want to be honest about the maturity of this, because resilience claims are cheap. I have not had the Pi crash during a live show and won’t pretend otherwise. The engine crash-recovery path is something I’ve validated through simulated failures and in-repo tests: kill the engine, let systemd restart it, reload the checkpoint, and assert that the rig comes back in the expected state.
What has already happened live is a different failure. During a set, the iPad app crashed. The engine on the Pi did not. The lights kept going.
That distinction matters. The operator surface failed, but the show stayed up. The Pi also held onto the crash telemetry until it had internet again, then flushed the queued events to Sentry. That gave me the actual production crash to fix instead of a guess. I fixed it from the Sentry data, took it to the next show, and the app didn’t crash there.

Actress for Parameter, 5/14/2026. Photo by Mariah Tiffany.
So the honest claim is narrower and better: the Pi crash-recovery path is engineered and tested under simulated failure, and a real live iPad-app crash stayed contained, produced useful evidence later, and did not repeat at the next show.
I am being careful about the claim here. This is not “nothing bad can happen.” It is “the software is engineered to restart into the last persisted live state, with a bounded chance of being one event behind.”
That is a much more useful promise.
Reliability is mostly about choosing the right fallback
A lot of reliability work sounds impressive because it describes all the failure you prevented. I think the harder and more honest part is naming the failure you are willing to live with.
For this rig, I was willing to live with:
- at most one uncheckpointed state change after a badly timed crash
- a reconnect sequence for both controller apps
- a brief restart window while the process comes back
I was not willing to live with:
- losing the recovered live state entirely
- restarting into a blank rig
- tying recovery to manual intervention on the Pi
Once those constraints were clear, the checkpoint design was not very mysterious.
The next piece is the protocol that lets two controllers reconnect, resync, and behave like clients of one authoritative system instead of two competing sources of truth.